
慢慢道来……
原来,对于Linkin这样的互联网企业来说,用户和网站上产生的数据有三种:
- 需要实时响应的交易数据,用户提交一个表单,输入一段内容,这种数据最后是存放在关系数据库(Oracle, MySQL)中的,有些需要事务支持。
- 活动流数据,准实时的,例如页面访问量、用户行为、搜索情况,这些数据可以产生啥?广播、排序、个性化推荐、运营监控等。这种数据一般是前端服务器先写文件,然后通过批量的方式把文件倒到Hadoop这种大数据分析器里面慢慢整。
- 各个层面程序产生的日志,例如httpd的日志、tomcat的日志、其他各种程序产生的日志。码农专用,这种数据一个是用来监控报警,还有就是用来做分析。
Linkin的牛逼之处,就在于他们发现了原先2,3的数据处理方式有问题,对于2而言,原来动辄一两个钟头批处理一次的方式已经不行了,用户在一次购买完之后最好马上就能看到相关的推荐。而对于3而言,传统的syslog模式等也不好用,而且很多情况下2和3用的是同一批数据,只是数据消费者不一样。
这2种数据的特点是:
- 准实时,不需要秒级响应,分钟级别即可。
- 数据量巨大,是交易数据的10倍以上。
- 数据消费者众多,例如评级、投票、排序、个性化推荐、安全、运营监控、程序监控、后期报表等
于是,Linkin就自己开发了一套系统,专门用来处理这种性质的数据,这就是Kafka
那么,在整个实践过程中Linkin做了什么样的设计,解决了什么问题?
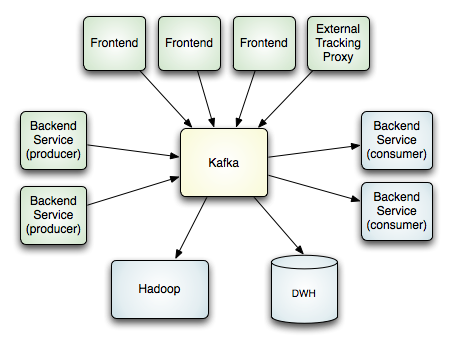
首先看下数据流动图:
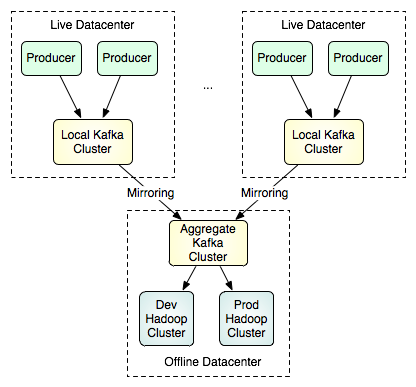
多数据中心怎么管理数据:
集群本身的架构图

Kafka内部架构图,分为数据产生者(Producer),数据中间者(Broker),数据消费者(Consumer)
显然,这是一个集群的发布/订阅系统,有如下几个特点
- 生产者是推数据(Push),消费者是拉数据(Pull)。存在数据复用,在Linkin平均生产1条消息会被消费5.5次。
- 数据生产者和数据消费者的速度不对等,所以要把数据沉淀在Kafka内慢慢处理,Linkin一般在集群内放7天的数据。
- 性能上追求高吞吐,保证一定的延时性之内。这方面做了大量优化,包括没有全局hash,批量发送,跨数据中心压缩等等。
- 容错性上使用的“至少传输一次”的语义。不保证强一次,但避免最多传一次的情况。
- 集群中数据分区,保证单个数据消费者可以读到某话题(topic)的某子话题(例如某用户的数据)的所有数据,避免全局读数据
- 数据规范性,所有数据分为数百个话题,然后在数据的源头——生产者(Producer)这边就用Schema来规范数据,这种理念使得后期的数据传输、序列化、压缩、消费都有了统一的规范,同时也解决了这个领域非常麻烦的数据版本不兼容问题——生产者一改代码,消费者就抓瞎。
- 用于监控,这个系统的威力在于,前面所有生产系统的数据流向,通过这个系统都能关联起来,用于日常的运营也好,用于数据审计,用于运维级别的监控也好都是神器啊!
所以,Kafka的设计基本上目前这个领域的唯一选择。我也看了很多其他实现,包括:
scribe(Facebook) | 2 | C++ | 已停止更新,不建议使用 flume(Apache, Cloudera) |1 | Java | 配置较重 chukwa(Hadoop) |12 | Java | 2012发布最后一版,不建议使用 fluentd |1 | Ruby | 比较活跃,看起来不错 logstash |12345| JRuby | 功能全,据说有不少小bug splunk |12345| C/Python | 商业闭源,功能强大,可做参考 timetunnel(Alibaba) | 2 | Java | 基于thrift,10年左右成熟 kafka(Linkin) | 2 4 | Scala | 性能强劲,设计巧妙,可以作为基础设施 Samza(Linkin) |12345| | =Kafka+YARN+Hadoop rabbitmq/activemq/qpid | 2 | Java | 传统消息中间件 Storm(twitter) | 3 | Clojure | 实时计算系统 Jstorm(Alibaba) | 3 | Java | storm的Java版,据说更稳定 S4(Yahoo) | 3 | Java | 2013年已停止维护 Streambase(IBM) | 3 | Java | 商业产品,作为参考 HStreaming | 3 | Java | 商业产品,作为参考 spark | 3 | Scala | 基于Hadoop mongodb | 4 | C++ | 比较浪费硬盘 mysql | 4 | C++ | 无需多说 hdfs/hbase | 4 | Java | 无需多说
- 数据采集组件
- 数据传输组件
- 数据实时计算/索引/搜索组件
- 数据存储/持久化组件
- 数据展示/查询/报警界面组件
从数据传输这块的设计理念来说,Kafka是最为先进的,



相关推荐
一共包含两个程序,分别是Kafka生产者工具、Kafka消费者工具。 1、使用bootstrap、userName、password连接kafka。 2、可使用text、json格式发送topic消息。 3、异步producer、customer,收发消息畅通无阻。 Kafka...
Kafka自LinkedIn开源以来就以高性能、高吞吐量、分布式的特性著称,本书以0.10版本的源码为基础,深入分析了Kafka的设计与实现,包括生产者和消费者的消息处理流程,新旧消费者不同的设计方式,存储层的实现,协调者...
Kafka自LinkedIn开源以来就以高性能、高吞吐量、分布式的特性著称,本书以0.10版本的源码为基础,深入分析了Kafka的设计与实现,包括生产者和消费者的消息处理流程,新旧消费者不同的设计方式,存储层的实现,协调者...
kafkapython教程_Kafka快速⼊门(⼗⼆)——Python客户端 Kafka快速⼊门(⼗⼆)——Python客户端 ⼀、confluent-kafka 1、confluent-kafka简介 confluent-kafka是Python模块,是对librdkafka的轻量级封装,⽀持Kafka ...
赠送jar包:kafka-clients-2.0.0.jar; 赠送原API文档:kafka-clients-2.0.0-javadoc.jar; 赠送源代码:kafka-clients-2.0.0-sources.jar; 赠送Maven依赖信息文件:kafka-clients-2.0.0.pom; 包含翻译后的API文档...
offsetExplore2 实际上是 Kafka 的一个工具,用于管理和监控 Apache Kafka 中的偏移量(offset)。在 Kafka 中,偏移量是用来标识消费者在一个特定分区中的位置的标识符,它可以用来记录消费者消费消息的进度。 ...
赠送jar包:kafka_2.11-0.10.0.1.jar; 赠送原API文档:kafka_2.11-0.10.0.1-javadoc.jar; 赠送源代码:kafka_2.11-0.10.0.1-sources.jar; 赠送Maven依赖信息文件:kafka_2.11-0.10.0.1.pom; 包含翻译后的API文档...
赠送jar包:kafka-clients-2.4.1.jar; 赠送原API文档:kafka-clients-2.4.1-javadoc.jar; 赠送源代码:kafka-clients-2.4.1-sources.jar; 赠送Maven依赖信息文件:kafka-clients-2.4.1.pom; 包含翻译后的API文档...
kafka
1、Kafka如何防止数据丢失 1)消费端弄丢数据 消费者在消费完消息之后需要执行消费位移的提交,该消费位移表示下一条需要拉取的消息的位置。Kafka默认位移提交方式是自动提交,但它不是在你每消费一次数据之后就...
使用Maven整合Kafka 包括生产者,消费者 Kafka各种配置 //1.设置参数 Properties props = new Properties(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "81.68.232.188:9092,81.68.232.188:9093,81...
Kafka自LinkedIn开源以来就以高性能、高吞吐量、分布式的特性著称,本书以0.10版本的源码为基础,深入分析了Kafka的设计与实现,包括生产者和消费者的消息处理流程,新旧消费者不同的设计方式,存储层的实现,协调者...
赠送jar包:kafka-clients-2.0.0.jar; 赠送原API文档:kafka-clients-2.0.0-javadoc.jar; 赠送源代码:kafka-clients-2.0.0-sources.jar; 赠送Maven依赖信息文件:kafka-clients-2.0.0.pom; 包含翻译后的API文档...
kafka_2.11-2.0.0.tgz, kafka_2.11-2.0.1.tgz, kafka_2.11-2.1.0.tgz, kafka_2.11-2.1.1.tgz, kafka_2.11-2.2.0.tgz, kafka_2.11-2.2.1.tgz, kafka_2.11-2.2.2.tgz, kafka_2.11-2.3.0.tgz, kafka_2.11-2.3.1.tgz, ...
本人在北美刚刚毕业,目前面试的几家大厂包括小公司在面试中都频繁的问道kafka这个技术,作为大数据开发或者java全栈的开发者来说,2020年很有必要系统的学习一下kafka. 1.[全面][Kafka2.11][jdk1.8][ZooKeeper3.4.6...
已编译 Kafka-Manager-1.3.3.22 linux下直接解压解压kafka-manager-1.3.3.22.zip到/opt/module目录 [root@hadoop102 module]$ unzip kafka-manager-1.3.3.22.zip 4)进入到/opt/module/kafka-manager-1.3.3.22/...
消费kafka某时间段消息用于分析问题,生产环境海量数据,用kafka-console-consumer.sh只能消费全量,文件巨大,无法grep。 代码来源于博主:BillowX_ ,感谢分享 原贴地址:...
Kafka是一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。在本课程中,你将学习到,Kafka架构原理、安装配置使用、详细的...
kafka连接工具
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-schema-registry-client -Dversion=6.2.2 -Dfile=/root/kafka-schema-registry-client-6.2.2.jar -Dpackaging=jar 官网下载地址 packages....